Quickstart
- Step 1: Download the code. Download the 2.4.
- Step 2: Start the server.
- Step 3: Create a topic.
- Step 4: Send some messages.
- Step 5: Start a consumer.
- Step 6: Setting up a multi-broker cluster.
- Step 7: Use Kafka Connect to import/export data.
- Step 8: Use Kafka Streams to process data.
.
In this manner, how do I run Kafka on Linux?
How to Install Apache Kafka on Ubuntu 18.04 & 16.04
- Step 1 – Install Java. Apache Kafka required Java to run.
- Step 2 – Download Apache Kafka.
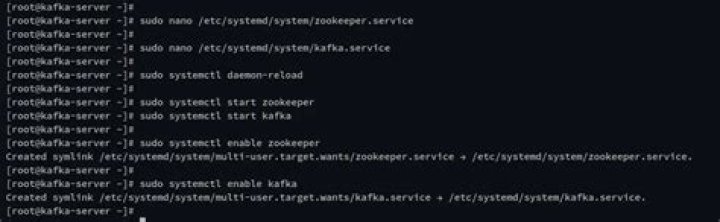
- Step 3 – Setup Kafka Systemd Unit Files.
- Step 4 – Start Kafka Server.
- Step 5 – Create a Topic in Kafka.
- Step 6 – Send Messages to Kafka.
- Step 7 – Using Kafka Consumer.
Secondly, how do I start zookeeper and Kafka in Ubuntu? Prerequisites :
- Download Apache Kafka :
- Extract Kafka and Change Directory :
- Start Apache Kafka :
- Start Zookeeper in Apache Kafka.
- Step 5: To Test Kafka:
- Step 5.1: Create Topic In Apache Kafka ,you can choose your topic name.
- Step 5.2: Create Producer In Apache Kafka.
- Step 5.3: Show list of topics.
Additionally, how do I start Kafka and zookeeper?
Kafka Setup
- Download the latest stable version of Kafka from here.
- Unzip this file.
- Go to the config directory.
- Change log.
- Check the zookeeper.
- Go to the Kafka home directory and execute the command ./bin/kafka-server-start.sh config/server.
- Stop the Kafka broker through the command ./bin/kafka-server-stop.sh .
How do I connect to Kafka?
Approach
- Install a Kafka server instance locally for evaluation purposes.
- Run the Kafka server and create a new topic.
- Configure the local Atom with the Kafka client libraries.
- Create an AtomSphere integration process to publish messages to the Kafka topic via Groovy custom scripting.
Can Kafka run without zookeeper?
Kafka 0.9 can run without Zookeeper after all Zookeeper brokers are down. After killing all three Zookeeper nodes the Kafka cluster continues functioning.How do I run Kafka locally?
Quickstart- Step 1: Download the code. Download the 2.4.
- Step 2: Start the server.
- Step 3: Create a topic.
- Step 4: Send some messages.
- Step 5: Start a consumer.
- Step 6: Setting up a multi-broker cluster.
- Step 7: Use Kafka Connect to import/export data.
- Step 8: Use Kafka Streams to process data.
How do I download Kafka on Linux?
This tutorial will help you to install Apache Kafka on Ubuntu 19.10, 18.04 & 16.04 systems.- Step 1 – Install Java.
- Step 2 – Download Apache Kafka.
- Step 3 – Setup Kafka Systemd Unit Files.
- Step 4 – Start Kafka Server.
- Step 5 – Create a Topic in Kafka.
- Step 6 – Send Messages to Kafka.
- Step 7 – Using Kafka Consumer.
Why does Kafka need zookeeper?
Kafka is a distributed system and uses Zookeeper to track status of kafka cluster nodes. Zookeeper also plays a vital role for serving many other purposes, such as leader detection, configuration management, synchronization, detecting when a new node joins or leaves the cluster, etc.What is Kafka good for?
Kafka is a distributed streaming platform that is used publish and subscribe to streams of records. Kafka is used for fault tolerant storage. Kafka is used for decoupling data streams. Kafka is used to stream data into data lakes, applications, and real-time stream analytics systems.What is Kafka and zookeeper?
Kafka is a distributed system and uses Zookeeper to track status of kafka cluster nodes. Zookeeper also plays a vital role for serving many other purposes, such as leader detection, configuration management, synchronization, detecting when a new node joins or leaves the cluster, etc.How does Kafka work?
How does it work? Applications (producers) send messages (records) to a Kafka node (broker) and said messages are processed by other applications called consumers. Said messages get stored in a topic and consumers subscribe to the topic to receive new messages.Is Kafka open source?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.How do I start my own ZooKeeper server?
Start ZooKeeper with the zkServer.sh command. Connect to the local ZooKeeper server with the following command: bin/zkCli.sh -server 127.0. 0.1:2181.Where does Kafka store data?
And in this case, it is the messages pushed into Kafka that are stored to disk. With reference to storage in Kafka, you'll always hear two terms, Partition and Topic. Partitions are the units of storage in Kafka for messages. And Topic can be thought of as being a container in which these partitions lie.How do I know if Kafka is installed?
Re: How to check Kafka version If you are using HDP via Ambari, you can use the Stacks and Versions feature to see all of the installed components and versions from the stack. Via command line, you can navigate to /usr/hdp/current/kafka-broker/libs and see the jar files with the versions.How do I start Kafka in Ubuntu?
How to Install Apache Kafka on Ubuntu 18.04 & 16.04- Step 1 – Install Java. Apache Kafka required Java to run.
- Step 2 – Download Apache Kafka.
- Step 3 – Setup Kafka Systemd Unit Files.
- Step 4 – Start Kafka Server.
- Step 5 – Create a Topic in Kafka.
- Step 6 – Send Messages to Kafka.
- Step 7 – Using Kafka Consumer.
How do I start Kafka ZooKeeper on Windows?
Important: Please ensure that your ZooKeeper instance is up and running before starting a Kafka server.- Go to your Kafka installation directory: C:kafka_2.11-0.9.0.0
- Open a command prompt here by pressing Shift + right click and choose the “Open command window here” option).
- Now type . inwindowskafka-server-start.
How do I get a list of Kafka topics?
- To start the kafka: $ nohup ~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties > ~/kafka/kafka.log 2>&1 &
- To list out all the topic on on kafka; $ bin/kafka-topics.sh --list --zookeeper localhost:2181.
- To check the data is landing on kafka topic and to print it out;
What is ZooKeeper server?
ZooKeeper is an open source Apache project that provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes.How many ZooKeeper nodes does Kafka have?
You need a minimum of 3 zookeepers nodes and 2 Kafka brokers to have a proper fault tolerant cluster. Recommended minimum fault tolerant cluster would be 3 Kafka brokers and 3 zookeeper nodes with replication factor = 3 on all topics.What is a topic in Kafka?
Kafka Topic. A Topic is a category/feed name to which messages are stored and published. Messages are byte arrays that can store any object in any format. As said before, all Kafka messages are organized into topics.What is Kafka technology?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.How do I download and install Kafka?
Download and Setup Kafka- Navigate to the Kafka configuration directory located under [kafka_install_dir]/config .
- Edit the file server. properties in a text editor.
- Find the “ log. dirs=/tmp/kafka-logs ” entry and change it to “ log. dirs=C:/temp/kafka-logs ”. Make sure to use forward slashes in the path name!