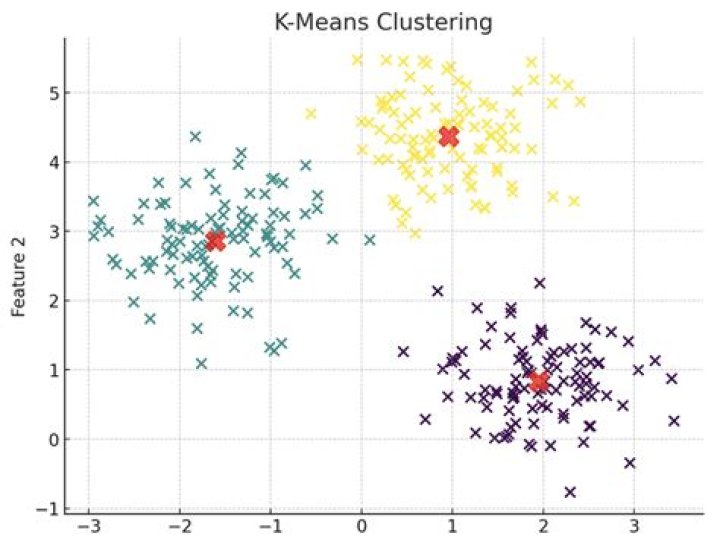
The way kmeans algorithm works is as follows: - Specify number of clusters K.
- Initialize centroids by first shuffling the dataset and then randomly selecting K data points for the centroids without replacement.
- Keep iterating until there is no change to the centroids.
.
Thereof, how do you do K means clustering?
K-Means Clustering Select k points at random as cluster centers. Assign objects to their closest cluster center according to the Euclidean distance function. Calculate the centroid or mean of all objects in each cluster. Repeat steps 2, 3 and 4 until the same points are assigned to each cluster in consecutive rounds.
One may also ask, how do you interpret K means clustering? Interpret the key results for Cluster K-Means
- Step 1: Examine the final groupings. Examine the final groupings to see whether the clusters in the final partition make intuitive sense, based on the initial partition you specified.
- Step 2: Assess the variability within each cluster.
Similarly, you may ask, how do you do K means clustering in Python?
Step 1 - Pick K random points as cluster centers called centroids. Step 2 - Assign each x i x_i xi to nearest cluster by calculating its distance to each centroid. Step 3 - Find new cluster center by taking the average of the assigned points. Step 4 - Repeat Step 2 and 3 until none of the cluster assignments change.
How do you prepare data for K means clustering?
Introduction to K-Means Clustering
- Step 1: Choose the number of clusters k.
- Step 2: Select k random points from the data as centroids.
- Step 3: Assign all the points to the closest cluster centroid.
- Step 4: Recompute the centroids of newly formed clusters.
- Step 5: Repeat steps 3 and 4.
Related Question Answers
Does K mean guaranteed to converge?
Show that K-means is guaranteed to converge (to a local optimum). Since the loss function is non-negative, the algorithm will eventually converge when the loss function reaches its (local) minimum. Let z = (z1,,zn) denote the cluster assignments for the n points.When to stop K means clustering?
There are essentially three stopping criteria that can be adopted to stop the K-means algorithm: Centroids of newly formed clusters do not change. Points remain in the same cluster. Maximum number of iterations are reached.What is clustering used for?
Clustering is a method of unsupervised learning and is a common technique for statistical data analysis used in many fields. In Data Science, we can use clustering analysis to gain some valuable insights from our data by seeing what groups the data points fall into when we apply a clustering algorithm.How do you find K in K means?
Compute clustering algorithm (e.g., k-means clustering) for different values of k. For instance, by varying k from 1 to 10 clusters. For each k, calculate the total within-cluster sum of square (wss). Plot the curve of wss according to the number of clusters k.How do you calculate K mean?
K-Means Clustering Select k points at random as cluster centers. Assign objects to their closest cluster center according to the Euclidean distance function. Calculate the centroid or mean of all objects in each cluster. Repeat steps 2, 3 and 4 until the same points are assigned to each cluster in consecutive rounds.What does inertia K mean?
K-means. The KMeans algorithm clusters data by trying to separate samples in n groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares (see below). Inertia makes the assumption that clusters are convex and isotropic, which is not always the case.Does K mean supervised?
K-means is a clustering algorithm that tries to partition a set of points into K sets (clusters) such that the points in each cluster tend to be near each other. It is supervised because you are trying to classify a point based on the known classification of other points.What is N_init in K means?
Maximum number of iterations of the k-means algorithm for a single run. n_init : int, default: 10. Number of time the k-means algorithm will be run with different centroid seeds.What means K return?
# Function: K Means # ------------- # K-Means is an algorithm that takes in a dataset and a constant # k and returns k centroids (which define clusters of data in the # dataset which are similar to one another).What is Wcss in K means?
sum of squares
What do you mean by clustering?
Clustering involves the grouping of similar objects into a set known as cluster. Objects in one cluster are likely to be different when compared to objects grouped under another cluster. Clustering is one of the main tasks in exploratory data mining and is also a technique used in statistical data analysis.Why Clustering is important in real life?
Clustering algorithms are a powerful technique for machine learning on unsupervised data. These two algorithms are incredibly powerful when applied to different machine learning problems. Both k-means and hierarchical clustering have been applied to different scenarios to help gain new insights into the problem.How do you test the accuracy of K means clustering?
To see the accuracy of clustering process by using K-Means clustering method then calculated the square error value (SE) of each data in cluster 2. The value of square error is calculated by squaring the difference of the quality score or GPA of each student with the value of centroid cluster 2.Do we need to normalize data for K means?
Normalization is not always required, but it rarely hurts. Some examples: K-means: K-means clustering is "isotropic" in all directions of space and therefore tends to produce more or less round (rather than elongated) clusters.How many clusters in K means?
The optimal number of clusters can be defined as follow: Compute clustering algorithm (e.g., k-means clustering) for different values of k. For instance, by varying k from 1 to 10 clusters. For each k, calculate the total within-cluster sum of square (wss).