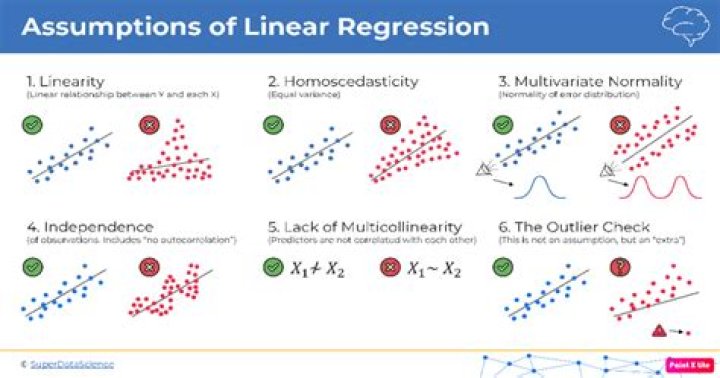
There are four assumptions associated with a linear regression model: - Linearity: The relationship between X and the mean of Y is linear.
- Homoscedasticity: The variance of residual is the same for any value of X.
- Independence: Observations are independent of each other.
.
Consequently, what are the assumptions for regression analysis?
The regression has five key assumptions: Linear relationship. Multivariate normality. No or little multicollinearity.
Furthermore, what assumptions are required for linear regression What if some of these assumptions are violated? If any of these assumptions is violated (i.e., if there are nonlinear relationships between dependent and independent variables or the errors exhibit correlation, heteroscedasticity, or non-normality), then the forecasts, confidence intervals, and scientific insights yielded by a regression model may be (at best)
Considering this, what are the assumptions of linear regression regarding residuals?
Multivariate Normality–Multiple regression assumes that the residuals are normally distributed. No Multicollinearity—Multiple regression assumes that the independent variables are not highly correlated with each other. This assumption is tested using Variance Inflation Factor (VIF) values.
What are the assumptions of OLS regression?
OLS Assumption 1: The linear regression model is “linear in parameters.” When the dependent variable (Y) is a linear function of independent variables (X′s) and the error term, the regression is linear in parameters and not necessarily linear in X ′ s X's X′s.
Related Question Answers
How do you test for multicollinearity in multiple regression?
One way to measure multicollinearity is the variance inflation factor (VIF), which assesses how much the variance of an estimated regression coefficient increases if your predictors are correlated. If no factors are correlated, the VIFs will all be 1.Why is autocorrelation bad?
In this context, autocorrelation on the residuals is 'bad', because it means you are not modeling the correlation between datapoints well enough. The main reason why people don't difference the series is because they actually want to model the underlying process as it is.What are the types of regression?
Types of Regression - Linear Regression. It is the simplest form of regression.
- Polynomial Regression. It is a technique to fit a nonlinear equation by taking polynomial functions of independent variable.
- Logistic Regression.
- Quantile Regression.
- Ridge Regression.
- Lasso Regression.
- Elastic Net Regression.
- Principal Components Regression (PCR)
How do you know if a linear regression is appropriate?
Simple linear regression is appropriate when the following conditions are satisfied. The dependent variable Y has a linear relationship to the independent variable X. To check this, make sure that the XY scatterplot is linear and that the residual plot shows a random pattern. (Don't worry.How do you know if a regression model is good?
4 Answers - Make sure the assumptions are satisfactorily met.
- Examine potential influential point(s)
- Examine the change in R2 and Adjusted R2 statistics.
- Check necessary interaction.
- Apply your model to another data set and check its performance.
What is the general form for the regression line used in statistics?
A linear regression line has an equation of the form Y = a + bX, where X is the explanatory variable and Y is the dependent variable. The slope of the line is b, and a is the intercept (the value of y when x = 0).Why normality assumption is important in regression?
We have to use 'Generalised Linear Models' if we want to relax the normality assumptions. Put slightly differently, the Simple Linear Regression model needs the normality assumption because it is a model for only quantities that are normal! A linear regression requires residuals to be normally distributed.What do you mean by autocorrelation?
Autocorrelation, also known as serial correlation, is the correlation of a signal with a delayed copy of itself as a function of delay. Informally, it is the similarity between observations as a function of the time lag between them.What do residuals tell us?
Residuals help to determine if a curve (shape) is appropriate for the data. A residual is the difference between what is plotted in your scatter plot at a specific point, and what the regression equation predicts "should be plotted" at this specific point.What is normality assumption?
What is Assumption of Normality? Assumption of normality means that you should make sure your data roughly fits a bell curve shape before running certain statistical tests or regression. The tests that require normally distributed data include: Independent Samples t-test.What is the linearity assumption?
Linearity – we draw a scatter plot of residuals and y values. If the residuals are not skewed, that means that the assumption is satisfied. Even though is slightly skewed, but it is not hugely deviated from being a normal distribution. We can say that this distribution satisfies the normality assumption.Why is Homoscedasticity important in regression analysis?
The idea is to give small weights to observations associated with higher variances to shrink their squared residuals. Weighted regression minimizes the sum of the weighted squared residuals. When you use the correct weights, heteroscedasticity is replaced by homoscedasticity.How do you test for Multicollinearity?
Multicollinearity can also be detected with the help of tolerance and its reciprocal, called variance inflation factor (VIF). If the value of tolerance is less than 0.2 or 0.1 and, simultaneously, the value of VIF 10 and above, then the multicollinearity is problematic.What are the assumptions for logistic and linear regression?
Some Logistic regression assumptions that will reviewed include: dependent variable structure, observation independence, absence of multicollinearity, linearity of independent variables and log odds, and large sample size.What is Vif in statistics?
In statistics, the variance inflation factor (VIF) is the quotient of the variance in a model with multiple terms by the variance of a model with one term alone. It quantifies the severity of multicollinearity in an ordinary least squares regression analysis.How do you read Durbin Watson test?
The Durbin-Watson statistic will always have a value between 0 and 4. A value of 2.0 means that there is no autocorrelation detected in the sample. Values from 0 to less than 2 indicate positive autocorrelation and values from from 2 to 4 indicate negative autocorrelation.What does R Squared mean?
R-squared is a statistical measure of how close the data are to the fitted regression line. It is also known as the coefficient of determination, or the coefficient of multiple determination for multiple regression. 100% indicates that the model explains all the variability of the response data around its mean.What are the most important assumptions in linear regression?
The regression has five key assumptions: Linear relationship. Multivariate normality. No or little multicollinearity.What violates the assumptions of regression analysis?
Potential assumption violations include: Implicit independent variables: X variables missing from the model. Lack of independence in Y: lack of independence in the Y variable. Outliers: apparent nonnormality by a few data points.